Tillerless Helm v2
Helm really became a de-facto as Kubernetes Package Manager.
Helm is the best way to find, share, and use software built for Kubernetes as it states on https://helm.sh.
That's true and sounds very cool.
Since Helm v2, helm got a server part called The Tiller Server which is an in-cluster server that interacts with the helm client, and interfaces with the Kubernetes API server. The server is responsible for the following (copypasta from https://helm.sh):
- Listening for incoming requests from the Helm client
- Combining a chart and configuration to build a release
- Installing charts into Kubernetes, and then tracking the subsequent release
- Upgrading and uninstalling charts by interacting with Kubernetes
Default Helm + Tiller setup
By default helm init installs a Tiller deployment to Kubernetes clusters and communicates via gRPC, and it is up to you to make Tiller more secure.
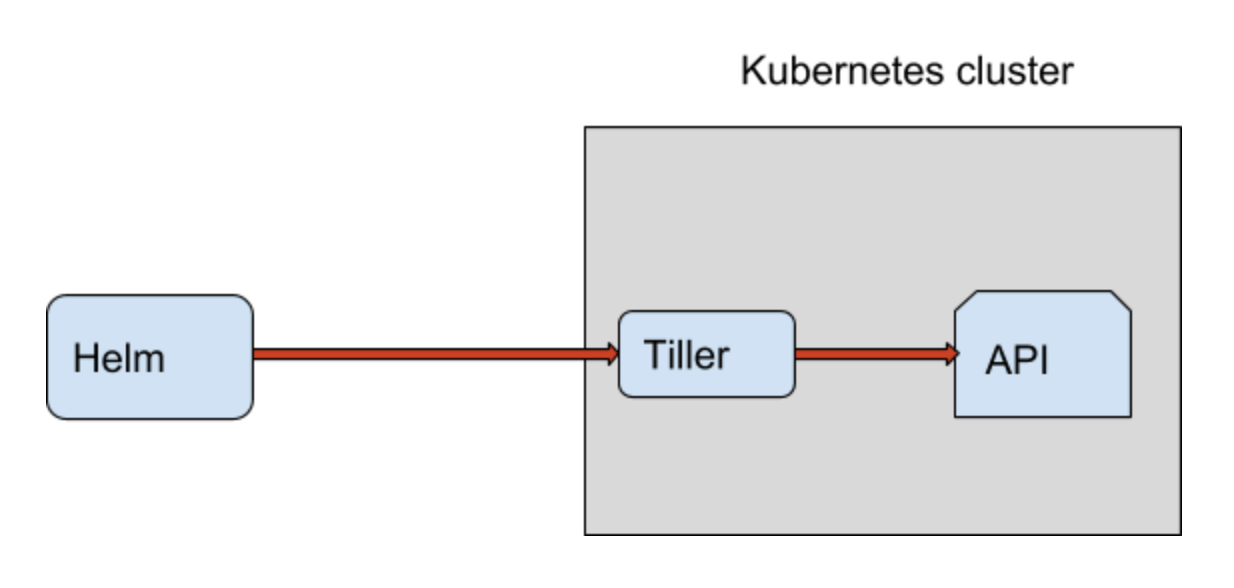
In a nutshell, the client is responsible for managing charts, and the server is responsible for managing releases.
It looks as a nice setup. Which of course works very well, but has some security issues, and the main one is that tiller runs in your Kubernetes cluster with full administrative rights - which is a risk is somebody gets unauthorised access to the cluster. If we bring multi tiller setup e.g. each team gets it's tiller then it gets worse with TLS and etc issues.
Helm v3
We had Helm Summit last February where the community voted that Helm v3 should be Tillerless. You can read the Helm v3 Design Proposal here. Also Matt Butcher has written a nice article A First Look at the Helm v3 Plan which I recommend for more background.
Looking to the Helm v3 proposal it looks to have some nice features, and is going to be way more secure, but it is not released yet (you can test pre-alpha version already). But in the meantime we need to live on and use Helm v2 for our releases.
"Tillerless" Helm v2 setup
It looks like it is not so hard to have Tillerless Helm v2. So let me go to more details and explain how to make it work.
It is so easy to run helm and tiller on your workstation or in CI/CD pipelines without installing tiller to your Kubernetes cluster:
$ export TILLER_NAMESPACE=my-team-namespace
$ export HELM_HOST=localhost:44134
$ tiller --storage=secret
[main] 2018/07/23 15:52:29 Starting Tiller v2.10.0 (tls=false)
[main] 2018/07/23 15:52:29 GRPC listening on :44134
[main] 2018/07/23 15:52:29 Probes listening on :44135
[main] 2018/07/23 15:52:29 Storage driver is Secret
[main] 2018/07/23 15:52:29 Max history per release is 0
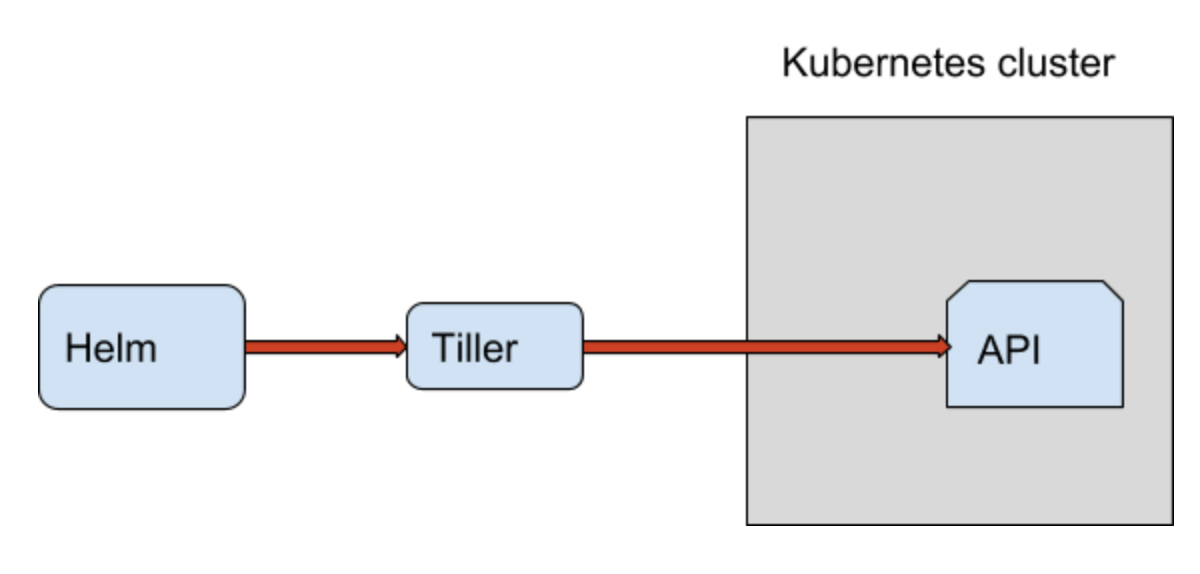
That's it, tiller uses the same kubeconfig as helm to connect to your cluster and as you see above you can pass the namespace which tiller will use to store helm releases. You can have many namespaces that way and just pass it when tiller starts. And a big plus not a single tiller instance running in your Kubernetes cluster. Your user's RBAC rules have to allow to store secrets/configmaps (tiller's storage) in that namespace and that's it, no more service accounts and other RBAc rules for your tiller. :)
Note: Initialize helm with helm init --client-only, flag --client-only is a must as otherwise you will get Tiller installed in to Kubernetes cluster.
"Tillerless" Helm v2 plugin
So how to make it even easier to install? I have made a simple "Tillerless" Helm plugin. If you aren't familiar with Helm plugins read it here.
Let's install the plugin:
$ helm plugin install https://github.com/rimusz/helm-tiller
Installed plugin: tiller
It has four simple commands start, start-ci, stop and run.
How to use this plugin locally
For the local development or accessing remote Kubernetes cluster use helm tiller start:
$ helm tiller start
Client: &version.Version{SemVer:"v2.10.0", GitCommit:"20adb27c7c5868466912eebdf6664e7390ebe710", GitTreeState:"clean"}
[main] 2018/07/23 16:08:07 Starting Tiller v2.10.0 (tls=false)
[main] 2018/07/23 16:08:07 GRPC listening on :44134
[main] 2018/07/23 16:08:07 Probes listening on :44135
[main] 2018/07/23 16:08:07 Storage driver is Secret
[main] 2018/07/23 16:08:07 Max history per release is 0
Server: &version.Version{SemVer:"v2.9.1", GitCommit:"20adb27c7c5868466912eebdf6664e7390ebe710", GitTreeState:"clean"}
Tiller namespace: kube-system
bash-3.2$
It will start the tiller locally and kube-system namespace will be used to store helm releases (the default tiller setup).
Also we can provide the namespace for the tiller:
$ helm tiller start my-team-namespace
Client: &version.Version{SemVer:"v2.10.0", GitCommit:"20adb27c7c5868466912eebdf6664e7390ebe710", GitTreeState:"clean"}
[main] 2018/07/23 16:08:38 Starting Tiller v2.10.0 (tls=false)
[main] 2018/07/23 16:08:38 GRPC listening on :44134
[main] 2018/07/23 16:08:38 Probes listening on :44135
[main] 2018/07/23 16:08:38 Storage driver is Secret
[main] 2018/07/23 16:08:38 Max history per release is 0
Server: &version.Version{SemVer:"v2.10.0", GitCommit:"20adb27c7c5868466912eebdf6664e7390ebe710", GitTreeState:"clean"}
Tiller namespace: my-team-namespace
bash-3.2$
It also opens a new bash shell with pre-set HELM_HOST=localhost:44134 so helm knows how to connect to tiller.
Now you are ready to deploy/update your helm releases.
You're done? Then just run:
$ exit
$ helm tiller stop
/Users/user/.helm/plugins/helm-tiller
Stopping Tiller..
Again you can pass another namespace and then deploy/update your other team helm releases.
How to use this plugin in CI/CD pipelines
But what about using the plugin in your CI/CD pipelines?
You have two options here.
The first one is very similar the one we looked at above, but this one doesn't start the pre-set bash shell.
$ helm tiller start-ci
$ export HELM_HOST=localhost:44134
Then your helm will know where to connect to Tiller and you do not need to make any changes in your CI pipelines.
And at the end of the pipeline include:
$ helm tiller stop
Nice, isn't it!
The second one is easy as to run helm tiller run which starts/stops tiller before/after the specified command:
$ helm tiller run helm list
$ helm tiller run my-team-namespace -- helm list
$ helm tiller run my-team-namespace -- bash -c 'echo running helm; helm list'
Let's check it out:
$ helm tiller run test -- bash -c 'echo running helm; helm list'
Installed Helm version v2.10.0
Installing Tiller v2.10.0 ...
x tiller
args=bash -c echo running helm; helm list
Client: &version.Version{SemVer:"v2.10.0", GitCommit:"20adb27c7c5868466912eebdf6664e7390ebe710", GitTreeState:"clean"}
[main] 2018/07/25 17:33:54 Starting Tiller v2.10.0 (tls=false)
[main] 2018/07/25 17:33:54 GRPC listening on :44134
[main] 2018/07/25 17:33:54 Probes listening on :44135
[main] 2018/07/25 17:33:54 Storage driver is Secret
[main] 2018/07/25 17:33:54 Max history per release is 0
Server: &version.Version{SemVer:"v2.10.0", GitCommit:"20adb27c7c5868466912eebdf6664e7390ebe710", GitTreeState:"clean"}
Tiller namespace: test
running helm
[storage] 2018/07/25 17:33:55 listing all releases with filter
NAME REVISION UPDATED STATUS CHART NAMESPACE
keel 1 Sun Jul 22 15:42:43 2018 DEPLOYED keel-0.5.0 default
Stopping Tiller...
Amazing! :)
Bonus feature: The plugin checks for installed helm and tiller versions, if they do not match then it downloads the correct tiller version file.
Using with GCP Cloud Build
Also I have made a few examples of using Tillerless Helm plugin in GCP Cloud Build pipelines with Helm tool builder.
Migration from Helm v2 to v3
Helm v3 got released, check it out my blog post How to migrate from Helm v2 to Helm v3.
